🕺🕺🕺 Follow Your Pose 💃💃💃
LIN, Xinxin
Introduction
Nowadays, Generating text-editable and pose-controllable character videos have an imperious demand in creating various digital human. Follow Your Pose is a useful Pose-Guided Text-to-Video text-to-video generation model allows users to create high-quality character videos from text descriptions while offering control over character poses using human skeletons. This article will introduce the different parameters of this AI-powered tool to guide you through creating your own video. To make the tool more accessible, steps will be demonstrate using openxlab at Openxlab:follow your pose. Or you can also try in colab Colab:follow your pose.
Model
Follow Your Pose is designed based on a pre-trained text-to-image model with powerful semantic editing and composition capabilities. The model features a two-stage training scheme that utilizes large-scale image pose pairs and diverse pose-free datasets. The schematic diagram of the model is shown below:
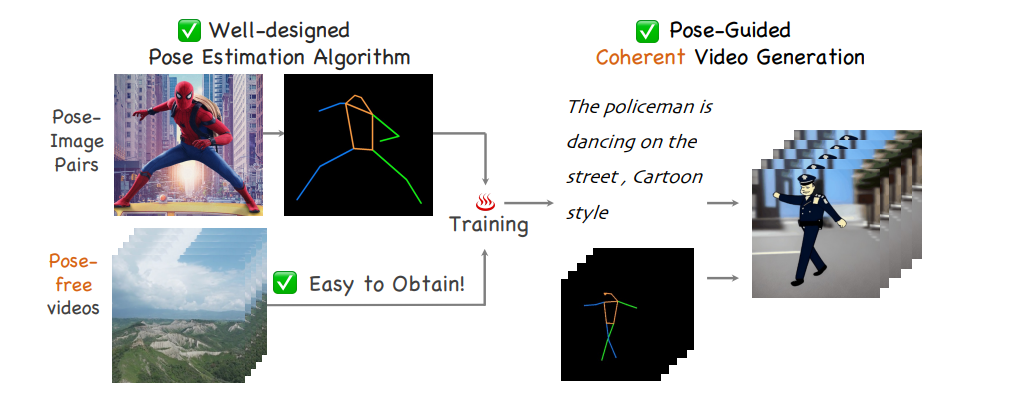
In the first stage, a zero-initialized convolutional pose encoder injects pose information into the network structure, while in the second stage, the image model is inflated to a 3D network adding the learnable temporal self-attention and reformed cross-frame self-attention blocks to learn temporal coherence from pose-free videos. The proposed approach generates creative and coherent videos while retaining the original model's conceptual combination ability. Therefore, the model can create high-quality character videos from text description and also control their pose via the given control signal.
Parameter Guided
There are five parameters in this model that you can edit: The type of input video, Temporal Crop offset & Sampling Stride, Spatial Crop offset, Text Prompt, and DDIM Parameters. In the next paragraphs, I will explain the usage of these parameters and post the demo video for you.
The type of input video
Here are two type of the input video: Raw Video or skeleton Video. The Raw video refers to the unprocessed video; the Skeleton video refers to the processed video with black background and preserved motion pose. As shown below, the left is the Raw video, and the right is the Skeleton video.
Raw Video
Skeleton video
The Skeleton video is significantly better than the Raw video regarding stability and efficiency. If the Raw video is used as input, the model must first calculate the corresponding Skeleton video, which will cause some errors. So I recommend using the Skeleton video directly as input to this model.
Temporal Crop offset & Sampling Stride
"Temporal Crop offset" and "Sampling Stride" refer to two parameters that control how the algorithm samples frames from a video to use for depth estimation and matting. Together, these parameters allow the model to efficiently and effectively sample frames from a video for depth estimation and matting, while also providing flexibility to adapt to different video datasets and tasks.
• Temporal Crop offset
"Temporal Crop offset" determines the starting point in time for sampling frames from the video. For example, if the temporal crop offset is set to 10, the algorithm will start sampling frames 10 frames after the beginning of the video. This can be useful for excluding frames at the beginning of a video that may not be relevant to the task at hand.
Input

Temporal Crop offset: 8

Temporal Crop offset: 32
• Sampling Stride
"Sampling Stride" determines the interval at which frames are sampled from the video. For example, if the sampling stride is set to 2, the algorithm will skip every other frame when sampling frames for depth estimation and matting. This can be useful for reducing the amount of computation required, as well as for avoiding redundant information in consecutive frames.
Input

Sampling Stride: 1

Sampling Stride: 20
Spatial Crop offset
"Spatial Crop offset" determines the starting point in the spatial domain for cropping the input video before passing it through the network for depth estimation and matting. The input video is first resized to a fixed size, and then cropped using a fixed spatial crop size. The spatial crop offset determines the position within the resized image where the cropping should start. For example, if the spatial crop offset is set to (10, 10), the cropping will start 10 pixels to the right and 10 pixels down from the top-left corner of the resized image.
Input
Zero offset

Right & Top crop: 200
Spatial cropping can be useful for several reasons. For example, it can help remove irrelevant or noisy regions from the input image that may negatively impact the depth estimation and matting performance. Additionally, it can help improve computational efficiency by reducing the size of the input image that needs to be processed by the network.
Text Prompt
"Text Prompt" is used to guide the graph generation process by constraining the set of possible graphs that the model can generate. By incorporating prior knowledge and preferences encoded in textual prompts, the model is able to generate more relevant and useful graphs for downstream tasks. Different text input will produce different effects, you can try the following input:
- "white rabbit dancing among flowers"
- "hulk at the beach"
If you have more novel ideas, welcome to try in Openxlab:follow your pose. But it is worth noting that the number of objects in the text input should not exceed the number of characters in the input video, which will cause unstable video generation. More intersting demo video are as follows:

A Panda on the sea

A Robot is dancing in Sahara desert

An Astronaut

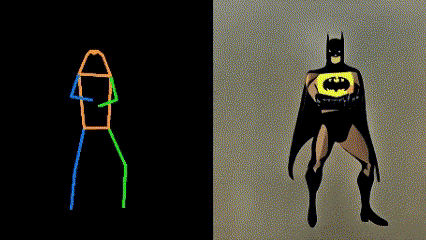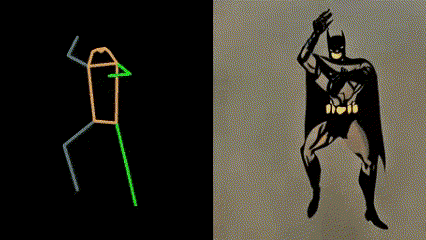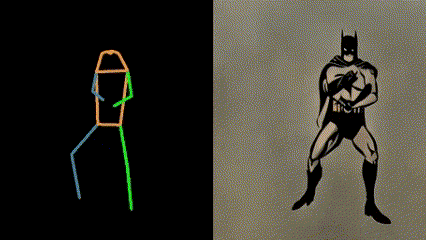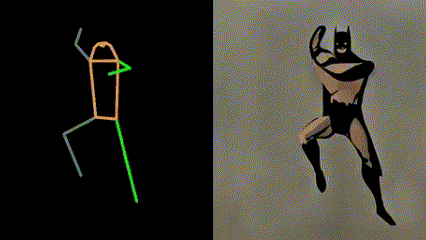

DDIM Parameters
"Number of Steps" and "CFG Scale" are two important hyperparameters that control the depth estimation and matting process. But it is worth noting that increasing their values will also increase the calculation time, so please adjust your expected values reasonably.
• Number of Steps
"Number of Steps" refers to the number of iterations that the algorithm performs to estimate the depth map and the alpha matte. Each iteration refines the current estimate by incorporating information from the input image and the estimated alpha matte and depth map from the previous iteration. Increasing the number of steps can improve the accuracy of the depth map and alpha matte estimation, but also increases the computational cost of the algorithm. Finding the optimal number of steps usually requires experimentation and validation on a held-out dataset.
• CFG Scale
"CFG Scale" refers to the scale of the coarse-to-fine guidance (CFG) network used in DDIM. The CFG network is a hierarchical network that helps refine the alpha matte and depth map estimate by providing coarse-to-fine guidance at different scales. Increasing the CFG scale can improve the accuracy of the depth map and alpha matte estimation, but also increases the computational cost of the algorithm. Finding the optimal CFG scale usually requires experimentation and validation on a held-out dataset.

Finally, I put the links of Openxlab: follow your pose, Hugging Face: follow your pose, Colab: follow your pose here for everyone to try. You are also welcome to visit the main website 🕺🕺🕺 Follow Your Pose 💃💃💃 for more academic details.
Conclusion
Collectively, Follow your pose tackle the problem of generating texteditable and pose-controllable character videos. The author design a new two-stage training scheme that can utilize the large-scale image pose pairs and the diverse pose-free dataset. It can generate novel and creative temporally coherent videos with the preservation of the conceptual combination ability of the original T2I model. Hopefully this tutorial provides guidance for effectively using 🕺🕺🕺 Follow Your Pose 💃💃💃.
Reference
Ma, Y., He, Y., Cun, X., Wang, X., Shan, Y., Li, X., & Chen, Q. (2023). Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos. arXiv preprint arXiv:2304.01186.