VideoFusion
DING, Kangyuan
Introduction
VideoFusion is a new DPM-based video generation method proposed by Alidamo in March this year.Compared to some previous video generating methods (Imagen Video, Make-A-Video, etc.), VideoFusion abandoned the common spatial/temporal super-resolution method and used DPM entirely to generate images and video sequences. In this tutorial, you will get an overview of VideoFusion and some basic useful tips of generating prompts and tuning parameters which help you though creating your intended videos in diverse ways.
Model Description
This model is based on a multi-stage text-to-video generation diffusion model, which inputs a description text and returns a video that matches the text description. Only English input is supported due to its developing methods and training datasets. The text-to-video generation diffusion model consists of three sub-networks: text feature extraction, text feature-to-video latent space diffusion model, and video latent space to video visual space. The diffusion model adopts the Unet3D structure, and realizes the function of video generation through the iterative denoising process from the pure Gaussian noise video. Moreover, unlike standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation, this work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. This approach, enables the model to generate more realistic videos with richer details and better consistency in its content, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation.
How to build a good prompt?
Now I will show you how to generate short videos using the demo platform on Huggingface Space at https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis. First, we have to input our prompt. Prompt is the description or request that we give to generative AI. The description of the content of your video is supposed to be included in the prompt and you could also give more details such as modifiers and style. This basic structure works well: [subject] in the style of [style or aesthetic]. Treat the prompt as a starting point, then modify it to suit your needs.Here are some examples: “An astronaut riding a horse.” “Spiderman is surfing.”
"An astronaut riding a horse"
"Spiderman is surfing"
To tuning your prompt, here are two general helpful rules: (1) Be detailed and specific, and (2) Use powerful keywords. Using a prompt generator is also a great way to learn a step-by-step process and important keywords. It is essential for beginners to learn a set of powerful keywords and their expected effects. This is like learning vocabulary for a new language. You can also find a short list of keywords and notes here https://stable-diffusion-art.com/how-to-come-up-with-good-prompts-for-ai-image-generation/#Some_good_keywords_for_you. Here are some examples of tuning prompts with the same theme --- Monkey playing tennis.
"A monkey playing tennis"
"A monkey is playing tennis, giving a hard strike"
"A monkey practising tennis giving a smooth strike"
We could see that simple prompt like "A monkey playing tennis" is ambiguous to AI, which leads to mistakenly generate a video of a monkey playing tennis balls. In this case, I further give the AI a more accurate prompt in order to get the precise result as I imaging. Furthermore, the followings are 2 more practical tips to make your video diversified and highly realistic. You could use these keyword to produce various videos when playing around the generator. Movement is one of the hardest things to achieve with text-to-video AI. Generally, verbs help a lot. For more action and movement, try adding keywords like: • cinematic action • flying • speeding • running Here are two examples:"cinematic action, high speed car chase" and "flying, an astronaut riding a pegasus".
"cinematic action, high speed car chase"
"flying, an astronaut riding a pegasus"
Besides, try using camera-specific terms to produce unexpected good result which brings more variance to your video. Use macro lens as if you are really observing something and adding slow movements could generate a scene in a action movie: • camera angles (full shot, close up, etc.) • lens types (macro lens, wide angle, etc.) • camera movements (slow pan, zoom, etc.) Here are two more examples for your reference: "macro lens, frog on lilypad" "Aerial drone footage of a mountain range"
"macro lens, frog on lilypad"
"Aerial drone footage of a mountain range"
In general, try to explain camera movements simply. So instead of dolly shot, you would say something like zooming in over time or growing over time.
Advanced Options
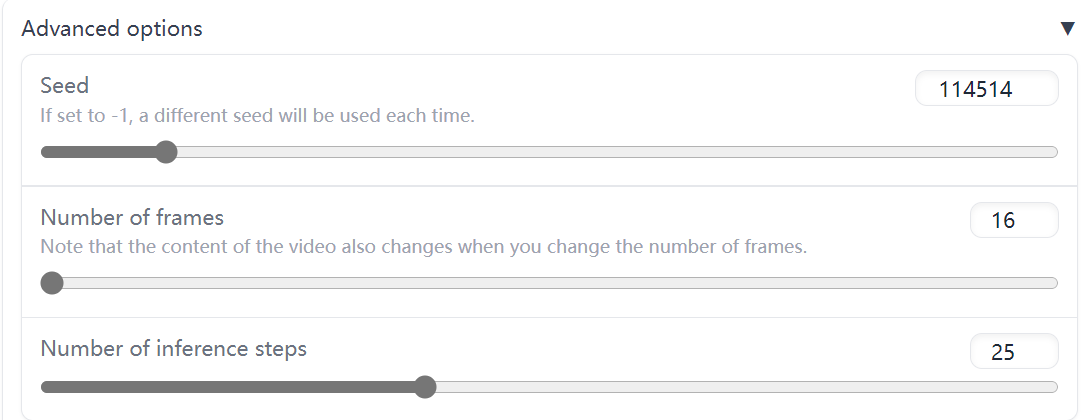 Before clicking on the start button, we could further set 3 parameters in order to get the video that we want.
A seed is a way of initializing the random number generator that is used to generate the video. It lets you reproduce the same result when you want to. All other settings being equal, if you use the same seed, you will get the same video. If you use a different seed, you will get a different image.
Although it is not a very common use case, it can come in handy with comparing various settings. For example, you can use the same seed for two different models and compare the results. Or you can use the same seed for two different schedulers and compare the results.
Number of frames - We all know videos are consisted of a sequence of frames. With more frames, your video could be smoother and its content could be more abundant.
The following triple videos are with the same prompt - "A cute puppy walking on the grass" but different frames.
Before clicking on the start button, we could further set 3 parameters in order to get the video that we want.
A seed is a way of initializing the random number generator that is used to generate the video. It lets you reproduce the same result when you want to. All other settings being equal, if you use the same seed, you will get the same video. If you use a different seed, you will get a different image.
Although it is not a very common use case, it can come in handy with comparing various settings. For example, you can use the same seed for two different models and compare the results. Or you can use the same seed for two different schedulers and compare the results.
Number of frames - We all know videos are consisted of a sequence of frames. With more frames, your video could be smoother and its content could be more abundant.
The following triple videos are with the same prompt - "A cute puppy walking on the grass" but different frames.
"16 frames"
"24 frames"
"32 frames"
Inference Steps - A diffusion probabilistic model starts with an image that consists of random noise. Then it continously denoises this image over and over again to steer it to the direction of your prompt. Inference steps controls how many steps will be taken during this process. The higher the value, the more steps that are taken to produce the frames in your video (also more time).Usually, the generating time will not grow significantly with the increasing of inference steps Although it is sometimes seen as a “quality slider” it's not necessarily that. Because after a certain number of steps, certain models in certain configurations will start introducing details that you might not like. The sweet spot for speed vs quality differs for each scheduler but 25 is usually a good starting point to experiment.
Inference steps = 25
Inference steps = 30
Inference steps = 35
Upscaling videos - To upscaling a video using videofusion, one should first generate a video using the lower resolution checkpoint cerspense/zeroscope_v2_576w with TextToVideoSDPipeline, which can then be upscaled using VideoToVideoSDPipeline and cerspense/zeroscope_v2_XL. Zeroscope are watermark-free model and have been trained on specific sizes such as 576x320 and 1024x576. For detailed code, here is the official tutorial given on huggingface. https://huggingface.co/docs/diffusers/main/en/api/pipelines/text_to_video#diffusers for your reference.

Conclusion
In general, Videofusion offers you a powerful generative AI tool for designing realistic videos from text prompts. Hopefully this tutorial provides guidance for using Videofusion in a practical to fulfill your need.
Reference
1. What are Diffusion Models? (2021) https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#:~:text=Diffusion%20models%20are%20inspired%20by,data%20samples%20from%20the%20noise 2. Luo, Z., Chen, D., Zhang, Y., Huang, Y., Wang, L., Shen, Y., Zhao, D., Zhou, J., & Tan, T. (2023). VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2303.08320