Drag GAN - Interactive Point-based Manipulation on the Generative Image Manifold
Muzi ZHANG
Introduction
Drag GAN is a new kind of GAN that allows user to modify multiple features such as shape, body pose, emotion of the images in a generative approach, users can achieve this by adding one more multiple pairs of points and DragGAN will perform a series of iterations that "drag" the handle points to the corresponding target points without modifying pixels outside a region specified by the user.
How to use
DragGAN include a GUI and users can do the image editing by simply clicking the image, then DragGAN will do multiple iterations so that the
image is transform slowly into the target.
 During the transformation, you can also stop at any step and modify the handle and target point(s), so that the image transformation can go on
with a different target.
During the transformation, you can also stop at any step and modify the handle and target point(s), so that the image transformation can go on
with a different target.
Since DragGAN is based on the StyleGAN2 model and perform image editing by modifying the mapped latent vector w of StyleGAN2 instead of doing this directly
on the input image, this tool can only handle generated images from StyleGAN2. Therefore, if user want to upload their own image, an extra GAN Inversion that
transform the image back to latent vector is required, which can probably affect the details of the original image.

Technical details
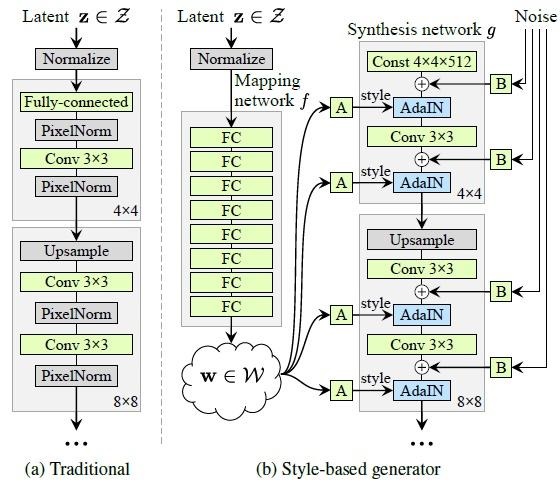
This tool is based on the StyleGAN2 architecture [Karras et al. 2020].
Different to common GAN models, the 512 dimentional latent vector 𝒛 ∈ N(0, 𝑰 ) is mapped to an intermediate
latent code 𝒘 via a mapping network in the StyleGAN2 architecture, which is used to control the style of the image. Then this vector
is fed to every layer in the synthesis network, with an addtional noise vector.
 DragGAN will do optimization base on the latent vector 𝒘 so that the handle points can move closer to the target point.
To move a handle point 𝒑𝑖 to the target 𝒕𝑖, the DragGAN supervise a small region around 𝒑𝑖 towards 𝒕𝑖, and design the loss function like this:
DragGAN will do optimization base on the latent vector 𝒘 so that the handle points can move closer to the target point.
To move a handle point 𝒑𝑖 to the target 𝒕𝑖, the DragGAN supervise a small region around 𝒑𝑖 towards 𝒕𝑖, and design the loss function like this:
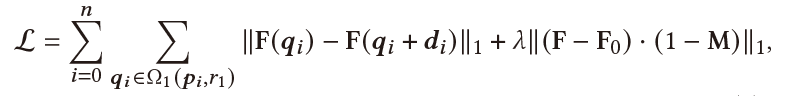 where F(𝒒) denotes the feature values of F at pixel 𝒒, 𝒅𝑖 is a normalized vector pointing from 𝒑𝑖 to 𝒕𝑖 (𝒅𝑖 = 0 if 𝒕𝑖 = 𝒑𝑖 ),
and F0 is the feature maps corresponding to the initial image. Note
that the first term is summed up over all handle points {𝒑𝑖 }. As the
components of 𝒒𝑖 +𝒅𝑖 are not integers, we obtain F(𝒒𝑖 +𝒅𝑖 ) via bilinear
interpolation.
where F(𝒒) denotes the feature values of F at pixel 𝒒, 𝒅𝑖 is a normalized vector pointing from 𝒑𝑖 to 𝒕𝑖 (𝒅𝑖 = 0 if 𝒕𝑖 = 𝒑𝑖 ),
and F0 is the feature maps corresponding to the initial image. Note
that the first term is summed up over all handle points {𝒑𝑖 }. As the
components of 𝒒𝑖 +𝒅𝑖 are not integers, we obtain F(𝒒𝑖 +𝒅𝑖 ) via bilinear
interpolation.
References
Xingang Pan [2023, May 18] Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold. https://arxiv.org/abs/2305.10973
Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De
Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero
Karras, and Gordon Wetzstein. 2022. Efficient Geometry-aware 3D Generative
Adversarial Networks. In CVPR.